
5.1 真核生物基因表达预览
The combined research efforts of many biologists, beginning with Darwin, in the mid-nineteenth century, through the mid-1940s, led to the discovery that genes, the instructions for building and maintaining organisms, reside on the chromosomes within the nucleus of eukaryotes. However, some controversy remained as to whether the genes were part of the cell‘s deoxyribonucleic acid (DNA) or were 蛋白质. The controversy began to dissipate in the late 1940s as the structure of DNA became clearer. X-ray crystallography of DNA (a method that shows the atomic arrangement in a molecule), performed by Rosalind Franklin and Maurice Wilkins, helped James Watson and Francis Crick more clearly define the structure of DNA and suggest that DNA could easily be rearranged and must be the location of genes. In April and May of 1953, Watson and Crick published two papers describing the structure of DNA and how the pairings of four nucleotide bases, adenine (A) with thymine (T) and guanine (G) with cytosine (C), formed the instructions for building 蛋白质. These 1953 publications by Watson and Crick describing the structure of DNA r进化ized biology. In the 60 years since their discovery, the basic mechanism of how the information in DNA is transferred to the amino acid sequence in a 蛋白质 has been completely worked out. In this first section of the chapter we explore that process.
5.1.1 Transcription of DNA produces complementary RNA
Gene expression begins when DNA transfers its information to ribonucleic acid (RNA) in a process called transcription (Figure 5.1). The synthesis of RNA from a DNA template has many similarities to the process of DNA replication that you learned about in Chapter 4. The double-stranded, double-helical DNA must open up and unwind to expose the base pairs. Then, one (but only one) of the DNA strands acts as the template for an RNA molecule, and, as in DNA replication, the nucleotides are added one by one. That is, the RNA is complementary to the DNA. There are, however, some significant differences between DNA replication and RNA transcription. Adenine in DNA pairs with the base uracil (U), as opposed to thymine, in forming the base sequence in RNA (Figure 5.2). That is, the four bases in RNA are adenine, uracil, cytosine, and guanine. The finished RNA molecule, known as an RNA transcript, is a single-stranded molecule. Another important difference between DNA replication and RNA transcription is the time needed to complete the process and the number of molecules that are produced. RNA molecules are typically only a few thousand nucleotides in length, compared with the 250 million base pairs of DNA found in a mediumsize chromosome.
 Figure 5.1 Transfer of genetic information from DNA to 蛋白质
Figure 5.1 Transfer of genetic information from DNA to 蛋白质
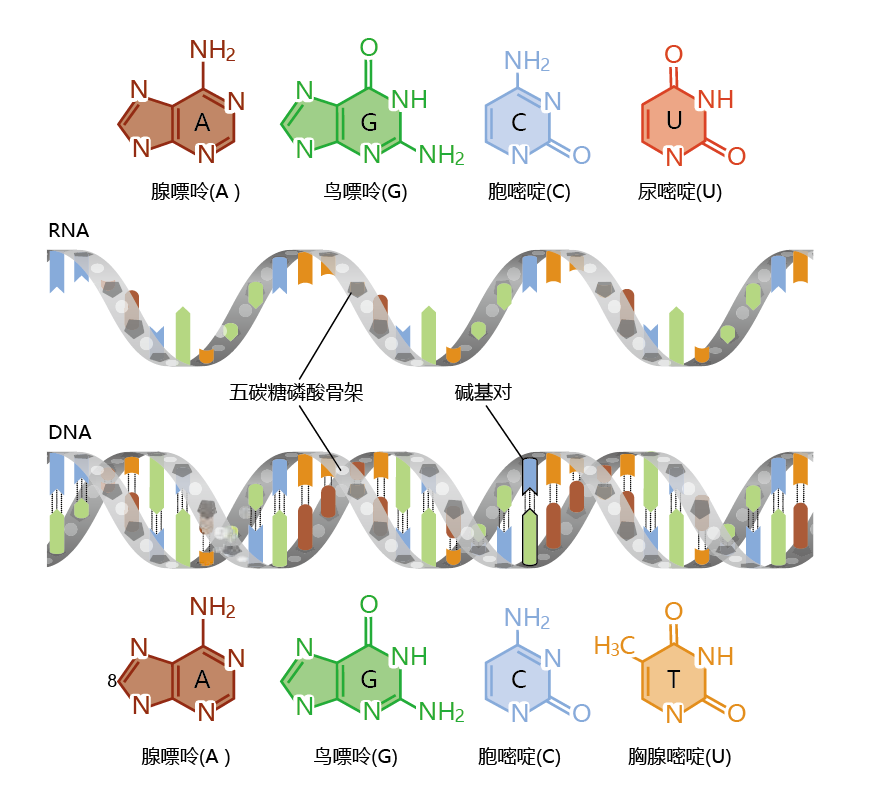
Figure 5.2 RNA and DNA. RNA (top) and DNA (bottom) consist of long chains of nucleotides, each of which consists of a nitrogenous base, a sugar, and a phosphate group. The four bases in DNA are adenine, guanine, cytosine, and thymine. RNA contains uracil instead of thymine.
Whereas DNA replication times are discussed in terms of hours, RNA transcription takes place in minutes. Several molecules of RNA polymerase, the enzyme that carries out transcription, can work on the same gene at the same time. As one RNA polymerase is finishing a transcript, another begins. This allows for several RNA transcripts to be made in a relatively short time, and thus the rapid synthesis of 蛋白质.
RNA polymerase begins its work when it recognizes a promoter region on the DNA, a specific sequence of nucleotides indicating the starting point for RNA synthesis (Figure 5.3). A single RNA polymerase performs several functions in building the RNA transcript. First, it opens up the double-stranded DNA to expose the bases. Then, the active site of the enzyme catalyzes a reaction that adds to the RNA a nucleotide that is complementary to the nucleotide in the DNA template—adding nucleotides, one at a time, in the 5'→3' direction. Finally, RNA polymerase rewinds the DNA into its double- helical structure. Elongation of the RNA transcript continues until RNA polymerase encounters another specific sequence of nucleotides on the DNA known as a termination site.
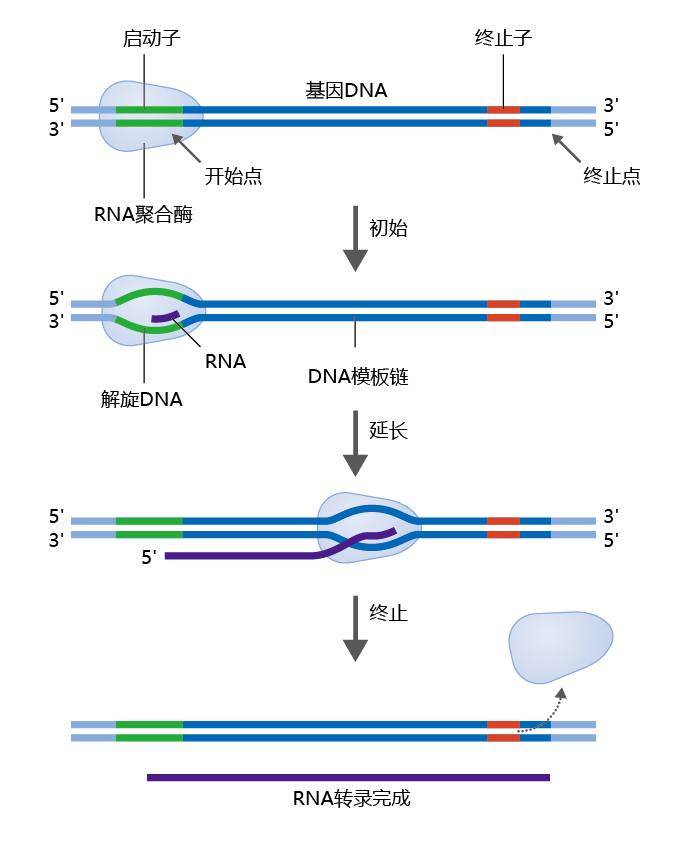
Figure 5.3 DNA transcription. RNA polymerase binds to the promoter region of DNA. During initiation, RNA polymerase unwinds the two DNA strands and initiates RNA synthesis. During elongation, the polymerase continues to assemble an RNA molecule with a nucleotide sequence complementary to that of the DNA template strand. When RNA polymerase reaches the termination site on the DNA, it unbinds from the DNA template and releases the newly made RNA transcript.
RNA polymerases recognize the promoter region of the DNA by its specific shape (Figure 5.4), which is formed by the binding to the promoter of specialized 蛋白质 called general transcription factors. The general transcription factors find the promoter region of a gene by locating a sequence known as the TATA box, because its sequence is composed primarily of the bases thymine (T) and adenine (A). Binding of the general transcription factors to the promoter region‘s TATA box causes the DNA to bend outward. RNA polymerase uses this bend as the landmark for beginning the transcription process. Once RNA polymerase binds to the DNA and begins transcription, the general transcription factors are released, to be used again for another gene transcription.
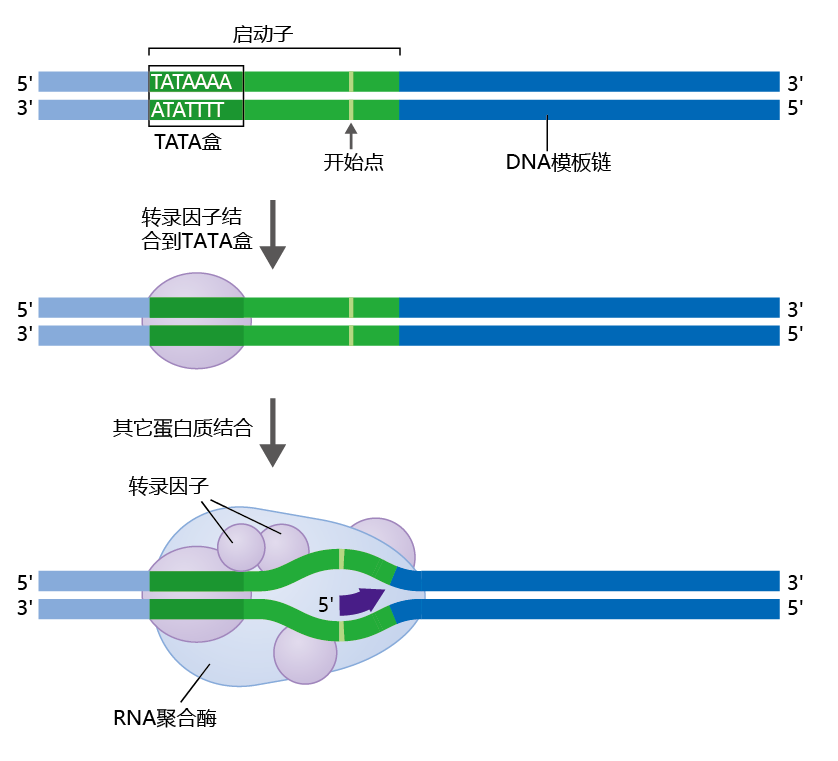
Figure 5.4 Transcription factors and the transcription initiation complex. Transcription factor 蛋白质 bind to the TATA box in the promoter region. The transcription factors mediate the binding of RNA polymerase and the initiation of transcription.
5.1.2 Eukaryotic cells modify RNA after transcription
The RNA transcript contains the entire base-sequence of the gene including its noncoding regions known as introns. Another type of RNA made from the RNA transcript, called messenger RNA (mRNA), is the one used by the cell as the template for 蛋白质 synthesis. Messenger RNA contains only exons, the coding regions of the gene. Thus, the introns must be removed from the RNA transcript before the molecule leaves the nucleus. The mechanism for removing introns is known as RNA splicing (Figure 5.5), which is carried out by other RNA molecules called small nuclear RNAs (snRNAs). The snRNAs are packaged with other 蛋白质 to form small nuclear ribonucleo蛋白质 (snRNPs, pronounced “snurups”). snRNPs combine with other 蛋白质 to form the spliceosome, the structure that carries out RNA splicing.
The spliceosome cleaves the RNA transcript (or pre-mRNA) at the 5′ end of an intron, as recognized by a few short nucleotide sequences common to most introns. The snRNAs then slide down the RNA until they find another set of unique nucleotide sequences at the 3′ end of the intron, and here they make another slice, freeing the intron from the RNA. The ends of the exons are then sealed together. This process continues until all the introns are removed from the RNA, and the premRNA becomes mRNA.
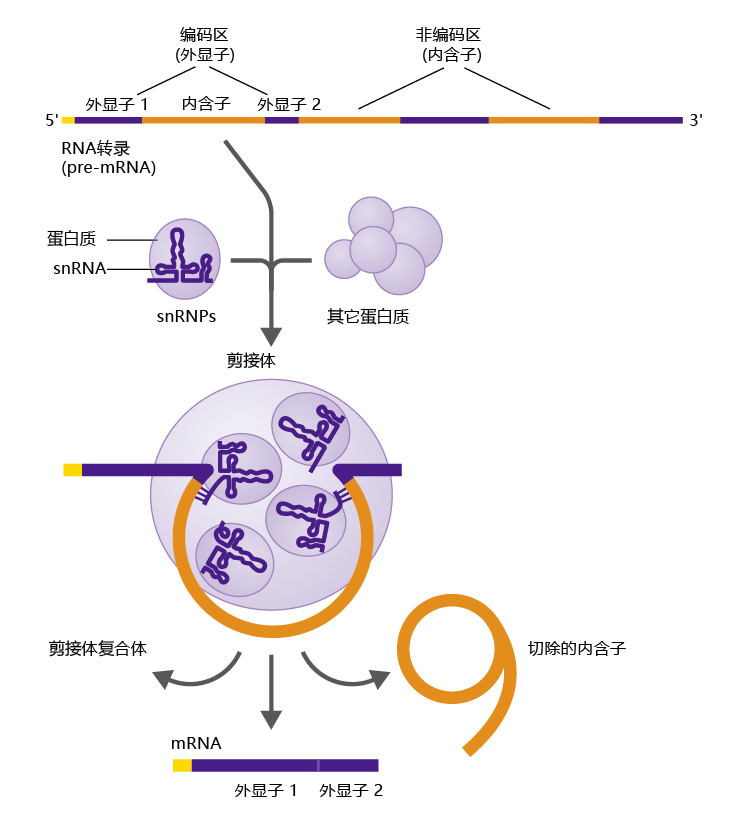 Figure 5.5 RNA splicing. The RNA transcript combines with small nuclear ribonucleo蛋白质 (snRNPs) and other 蛋白质 to form the spliceosome. The spliceosome cuts each end of the intron sequence, removing it from the transcript. The exons are spliced together, forming messenger RNA (mRNA).
Figure 5.5 RNA splicing. The RNA transcript combines with small nuclear ribonucleo蛋白质 (snRNPs) and other 蛋白质 to form the spliceosome. The spliceosome cuts each end of the intron sequence, removing it from the transcript. The exons are spliced together, forming messenger RNA (mRNA).
Synthesis of mRNA occurs in the nucleus whereas translation (synthesis of the 蛋白质 encoded by the DNA), the primary purpose of mRNA, takes place in the cytosol. Therefore, the mRNA must be transported out of the nucleus. Transport of mRNA into the cytosol presents a potential problem for the cell, because many RNA fragments, such as excised introns, are present in the nucleus after splicing has been completed. In other words, how does the nucleus recognize only the mRNA and then transport only this molecule out of the nucleus?
The nuclear envelope contains openings called nuclear pore complexes (Figure 5.6). These pores allow passage of a molecule having a specific structure, and this structure is created by binding 蛋白质 that are specific to mRNA. For example, completed and active mRNA contains unique regions of nucleotides characterized by strings of adenine bases called poly-A tails. The ubiquitous poly-A-binding 蛋白质 found in the nucleus bind to these regions, and the nuclear pore complexes recognize this complex as mRNA. Poly-A-binding 蛋白质 are just one of several types of 蛋白质 found in the nucleus that bind only to completed and active mRNA. Once the mRNA passes into the cytoplasm, the binding 蛋白质 are removed and degraded, as are the RNA fragments remaining in the nucleus.

Figure 5.6 RNA modification occurs after transcription. (A) Enzymes modify the ends of the mRNA molecule by adding a modified guanosine cap to the 5′ end and a poly-A tail to the 3′ end. (B) Two 蛋白质 —a binding 蛋白质 that attaches to the poly-A tail and a cap-binding 蛋白质 that binds to the 5′ end—form a complex with the completed mRNA molecule, allowing the nuclear pore complex to distinguish between RNA fragments and mRNA. Once in the cytosol, the cap-binding 蛋白质 is exchanged for a 蛋白质 synthesis initiation factor.
5.1.3 Translation is the RNA-directed synthesis of a 蛋白质
The nucleotide sequence of the mRNA is the code that is used for protein synthesis. The nucleotides are read in groups of three known as codons, and each group of three corresponds to a specific amino acid; this correspondence between codons and amino acids is known as the genetic code (TABLE 5.1). A single amino acid can have more than one codon; for example, the codons GCU, GCC, GCA, and GCG all code for the amino acid alanine (Ala). The codon AUG codes for methionine and the start of the 蛋白质编码信息,and three codons, UAA, UAG, and UGA, known as stop codons, end the 蛋白质-coding message.
TABLE 5.1 THE GENETIC CODE 
The mRNA does not directly bind to the amino acids. Rather, two specialized molecules known as adaptors—transfer RNA (tRNA) and aminoacyl-tRNA synthetase—are responsible for the process of translating the nucleotide message in the mRNA into the correct amino acid sequence of a 蛋白质. The tRNAs are small molecules, about 80 nucleotides in length. They have a site for linkage to the codon in the mRNA at one location and a site unique to the corresponding amino acid at another (Figure 5.7). Aminoacyl-tRNA synthetase is the enzyme that covalently couples the tRNA to its corresponding amino acid. A tRNA coupled to its amino acid is called a charged tRNA.
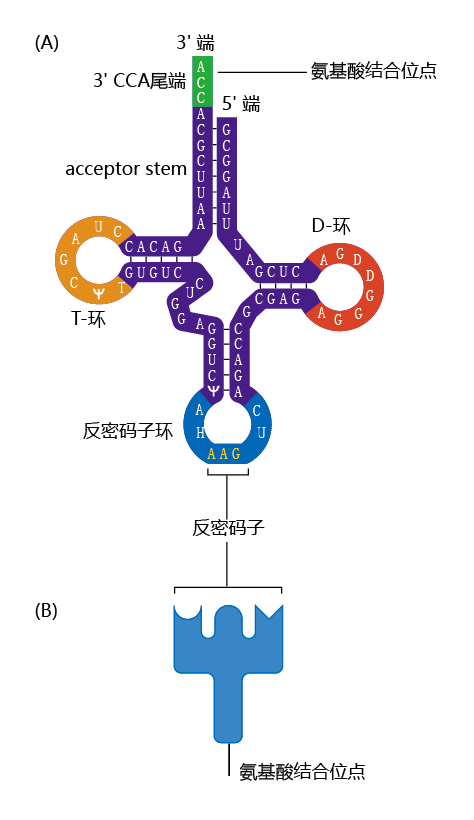
Figure 5.7 Structure of tRNA. (A) tRNA consists of a single strand of RNA that forms several double-stranded regions in which segments of the RNA base pair with each other. A single-stranded loop at the end of the molecule contains a triplet of bases called the anticodon. A short single strand at the opposite end is the site where an amino acid attaches to form the charged tRNA. (B) Schematic representation of the tRNA molecule.
So far, we‘ve seen that mRNA contains the genetic code for 蛋白质 synthesis and that tRNA, along with an aminoacyl-tRNA synthetase, brings the amino acid to the mRNA. The actual process of bonding the amino acids together to form the 蛋白质 is a much more complex process that requires 50–80 different 蛋白质 and a physical location that holds all the different molecules, including enzymes and other 蛋白质, together. The 蛋白质-manufacturing complex that houses all these 蛋白质 and provides the space for the process to take place is called the ribosome. Each cell contains millions of ribosomes, so that many different 蛋白质 or several copies of the same 蛋白质 can be synthesized simultaneously and with great speed (Figure 5.8)
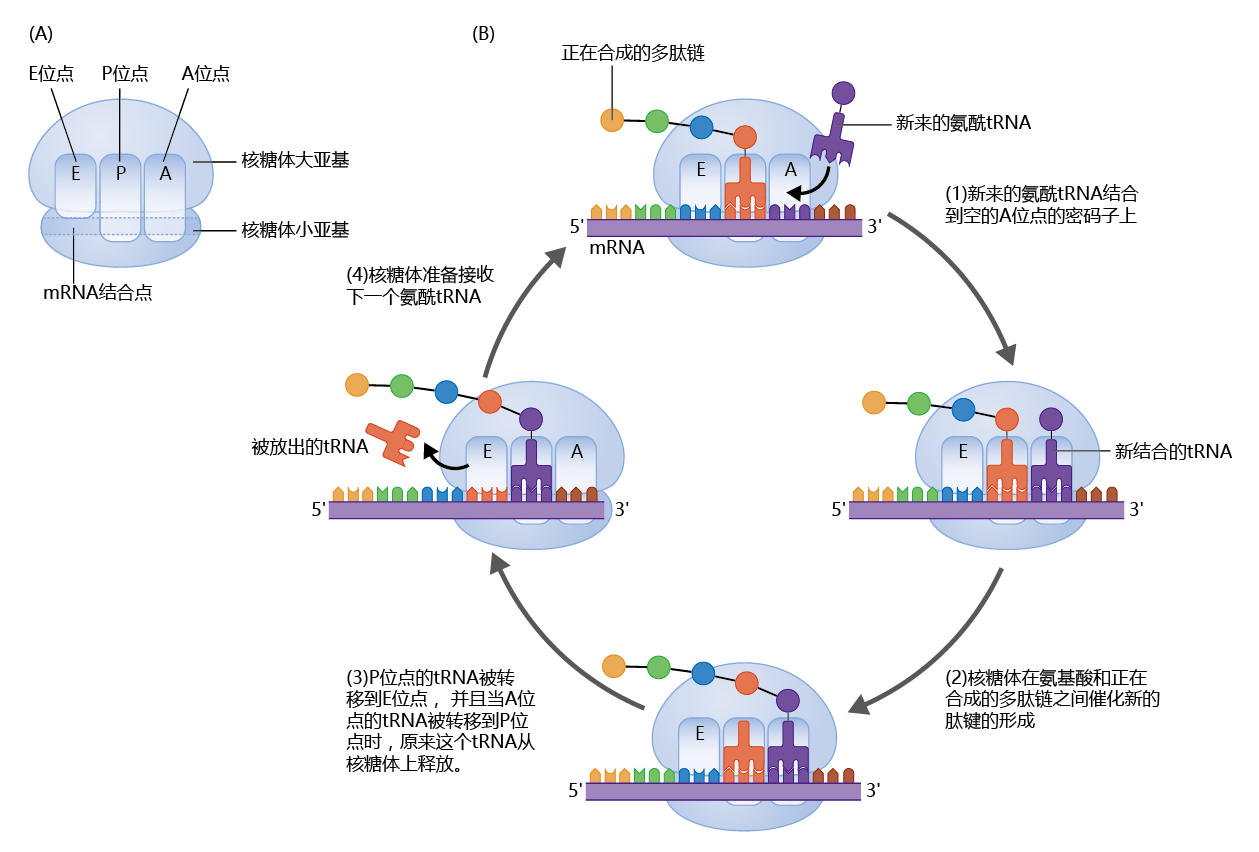
Figure 5.8 蛋白质 synthesis on the ribosome. (A) A ribosome consists of two subunits—the large subunit and the small subunit. The ribosome has an mRNA-binding site and three tRNA-binding sites, known as the P, A, and E sites. (B) Translation takes place in a four-step cycle. (1) The anticodon of an incoming charged tRNA pairs with the mRNA codon in the A site of the ribosome. (2) The charged tRNA donates its amino acid to the growing 蛋白质, using the energy of the high-energy bond created during the charging process. (3) The large subunit translocates (to the right, as shown here), moving the tRNAs from the P and A sites to the E and P sites, respectively, leaving the A site open for the next charged tRNA. The tRNA in the E site is enzymatically removed from the ribosome. The small subunit shifts (to the right) to match the large subunit, pulling the mRNA along. (4) The ribosome is now ready to receive the next charged tRNA in the A site, and the process starts again with step 1. This cycle continues until the ribosome encounters a stop codon in the mRNA, at which point the completed 蛋白质 is released from the ribosome.
5.1.4 蛋白质 can be modified or degraded after translation
When the ribosome releases the completed 蛋白质, noncovalent interactions among the 蛋白质‘s amino acids cause the 蛋白质 to fold upon itself, creating its tertiary structure. The tertiary structure is essential to the active state of the 蛋白质. Some 蛋白质 require modification after the translation process before they are completely active. There are several types of post-translational modification, but the two most common are phosphorylation, addition of a phosphate group, and glycosylation, addition of a glucose molecule. In general, 蛋白质 subject to post-translational modification are used as intracellular messengers and signals. That is, they signal other 蛋白质 what to do by the presence or absence of non–amino acid molecules bound to the 蛋白质. As you‘ll learn later in this chapter, the state of post-translational modification of a 蛋白质 known as DAF-16 has a significant role in the longevity characteristics of C. elegans.
A properly, efficiently functioning cell depends, to a large degree, on its ability to regulate the amount and structure of its constituent 蛋白质. Complex mechanisms have evolved in the eukaryotic cell to ensure that improperly folded or damaged 蛋白质 are removed and that the concentration of an individual 蛋白质 stays at the optimal level. These mechanisms involve thousands of 蛋白质 participating in hundreds of biochemical pathways. Here we discuss briefly some generalities common to most 蛋白质-degradation pathways (Figure 5.9) .
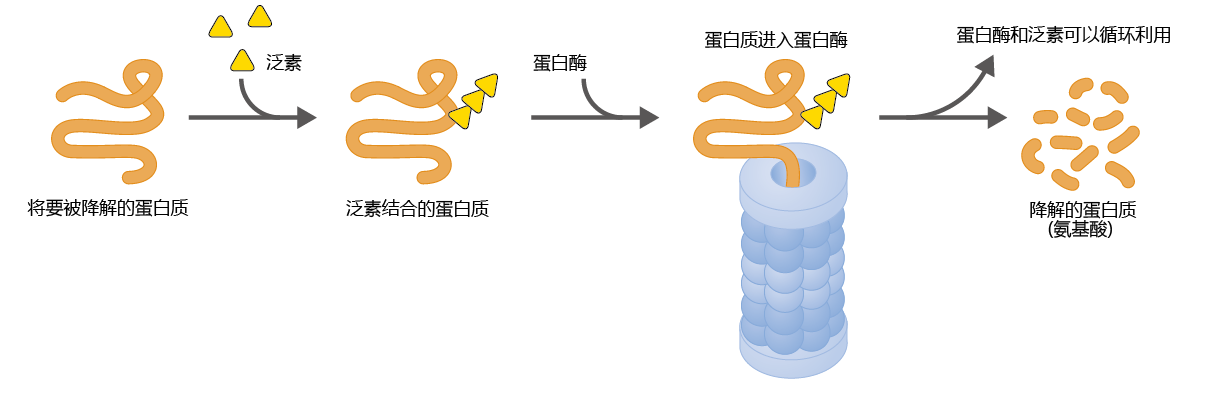
Figure 5.9 Degradation of a 蛋白质 by a proteasome. Small ubiquitin 蛋白质 are attached to the 蛋白质 to be degraded. The proteasome recognizes the ubiquitin-tagged (ubiquitinated) 蛋白质, unfolds it, and stores it in its central cavity. Enzymes within the proteasome then break apart the 蛋白质 into small peptides and amino acids, which are released back into the cytosol.
Maintenance of the correct tertiary structure of a 蛋白质—its active form—is assisted by a group of regulatory cytoplasmic 蛋白质 known as chaperones. Chaperones perform two major functions: (1) they help the 蛋白质 to fold correctly, and (2) if a 蛋白质 has not folded correctly or is damaged, they mark it for degradation with another 蛋白质 called ubiquitin. A large complex of enzymes and other 蛋白质 called the proteasome recognizes ubiquitin-marked 蛋白质. The cylindershaped proteasome contains enzymes called proteases that break the bonds, called peptide bonds, between the amino acids of 蛋白质. The amino acids released by this breakdown are returned to the intracellular amino acid pool to be used in another round of 蛋白质 synthesis. You will learn in Chapter 9 that a dysfunction in the 蛋白质-degradation pathways that involve chaperones and ubiquitin may be the underlying biochemical cause of Alzheimer‘s and Parkinson‘s diseases.